Overview


Embodied agents such as humans and robots are situated in a continual non-episodic world. Reinforcement learning (RL) promises a framework for enabling artificial agents to learn autonomously with minimal human intervention. However, current episodic RL routine takes the following form:
- Sample an initial state s.
- Let the agent run from s for a short period of time (typically 100 to 1000 steps).
- Update the agent (policy, model etc).
- Repeat till convergence.
This algorithmic routine relies on the existence of episodes, an assumption that breaks the autonomy of the learning system and cannot be realized without extrinsic interventions to reset the environment after every interaction. An overview of the algorithmic difference:
Environment for Autonomous RL (EARL): The goal of our proposed framework Autonomous RL (ARL) and the accompanying benchmark EARL is to encourage research that develops algorithms for the continual non-episodic world, moving towards building truly autonomous embodied agents. At a high level, algorithms are evaluated on EARL under the following conditions:
- Sample an initial state s.
- With probability 1-ε, the agent runs from s according to the environment dynamics.
- With probability ε, an extrinsic intervention resets the environment to a newly sampled initial state.
In the EARL environments, ε is very low (10-5 to 10-6), such that the agents operate autonomously for several hundred thousands of steps. EARL provides a diverse set of environments to evaluate autonomous learning algorithms, offering two modes for evaluating the algorithms:
- Deployment Evaluation: The learned policy is intermittently evaluated from the initial state, representing the performance of the policy if it were deployed. Algorithms are evaluated based on how quickly the deployed performance of the policy improves.
- Continuing Evaluation: Algorithms are evaluated on the rate at which they accumulate the reward during their lifetimes.
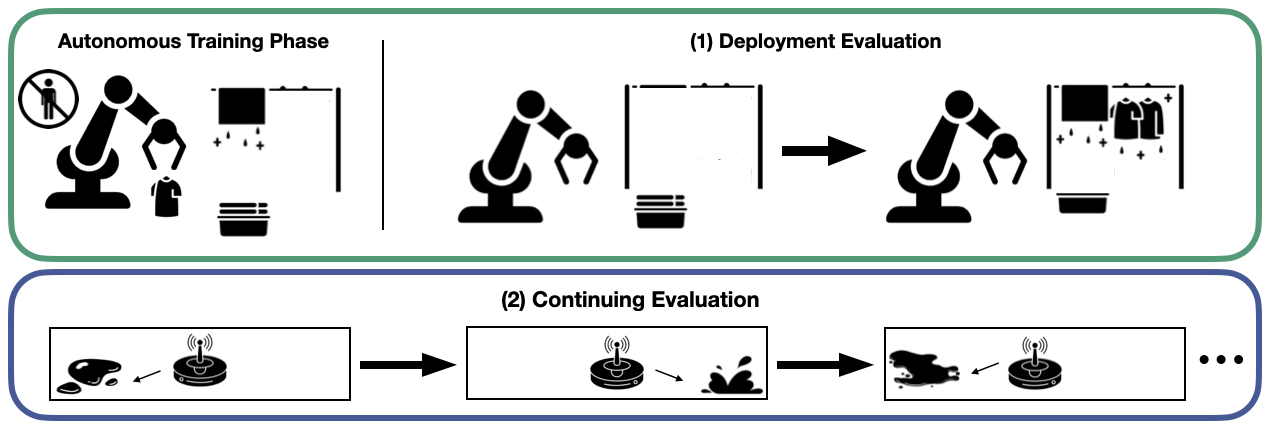
As motivation, consider training a robot to clean a kitchen. We might want to evaluate how well the robot keeps the kitchen clean over it's entire lifetime, as well as how it performs if it is deployed for a specific cleaning task, like turning off the stove. Both objectives are important, but may not always align, so EARL returns both values for all environments.
The EARL benchmark consists of 6 simulated environments, ranging from the aforementioned kitchen environment to dexterous hand manipulation and locomotive robots. Learn more about them on our environments page →